
electronique-news.com
17
'22
Written on Modified on
Arrêtez de déplacer les données : déplacez plutôt l’algorithme – Mise en œuvre de l’approche « computational storage »
L’utilisation croissante de réseaux neuronaux d’apprentissage automatique augmente de fait la nécessité de traiter des quantités colossales de données. En matière de traitement informatique, l’usage a toujours été de déplacer les données vers l’endroit où elles seront traitées par un algorithme.

Or, de grands ensembles de données de l’ordre du pétaoctet sont aujourd’hui chose courante. Lorsque l’on considère que l’algorithme qui doit traiter cette masse de données ne pèse lui-même parfois que quelques dizaines de mégaoctets, l’idée de traiter les données plus près de l’endroit où elles sont stockées prend tout son sens. Le présent article se penche sur les concepts et l’architecture qui sous-tendent le computational storage (c’est-à-dire le stockage avec capacité de calcul). Nous verrons également en quoi l’accélération matérielle et les performances offertes par les processeurs dédiés au computational storage (CSP) constituent un véritable atout pour exécuter une grande variété de tâches nécessitant une forte capacité de calcul sans cause de surcharge du processeur hôte.
Vers l’infini et au-delà : des ensembles de données de plus en plus imposants
Ces dernières années ont vu une augmentation spectaculaire de l’utilisation des algorithmes de réseau de neurones, en particulier pour les applications automobiles, industrielles, de sécurité et grand public. Certains algorithmes, comme ceux utilisés par les capteurs IoT reposant sur l’informatique en périphérie, occupent peu d’espace et traitent très peu de données. L’utilisation d’algorithmes d’apprentissage automatique à la périphérie connaît même une croissance exponentielle à mesure que les fonctionnalités des microcontrôleurs embarqués à faible consommation d’énergie et les capacités des « moteurs » de réseau neuronal se perfectionnent. Les applications industrielles et automobiles de détection d’objets ont principalement recours au traitement de la vision et s’appuient pour cela sur un type de réseau neuronal spécifique appelé réseau neuronal convolutif.
Dans une application industrielle, par exemple, un simple traitement de la vision peut vérifier si les étiquettes sont correctement apposées sur les bouteilles qui défilent à grande vitesse sur une ligne d’embouteillage, mais il peut aussi réaliser des tâches plus complexes, comme trier des pommes (ou tout autre fruit) en fonction de leur taille, de leur état ou de leur variété. Dans le secteur automobile, les applications de traitement de la vision en temps réel font un usage encore un peu plus poussé des algorithmes de réseau de neurones en étant capables d’identifier et de classifier de multiples objets. Les réseaux neuronaux sont également très utilisés dans le milieu de la recherche scientifique lorsqu’il s’agit de manipuler de très grands ensembles de données, par exemple dans le cadre de l’analyse des données collectées à partir de satellites de télédétection ou d’un réseau mondial de capteurs sismiques.
Dans le domaine de l’apprentissage automatique, beaucoup d’applications sont perfectionnées en vue de prédire les classifications et les observations avec un degré de probabilité plus élevé. Cela nécessite d’utiliser des ensembles de données d’apprentissage plus volumineux et donc de devoir déplacer, traiter et stocker de façon répétée jusqu’à 1 Po de données.
Le computational storage
Les périphériques de stockage basés sur la mémoire flash NAND se sont énormément popularisés au cours de la dernière décennie. Initialement réservée à des applications de stockage haut de gamme, l’utilisation de mémoire NAND dans des disques durs à semi-conducteurs est désormais si répandue que ces derniers ont supplanté les disques magnétiques traditionnels dans la plupart des ordinateurs portables et de bureau. Cette méthode de stockage, associée à l’avènement du protocole NVMe (pour non-volatile memory express) et à l’évolution des débits de données de la connectivité PCIe, permet d’envisager autrement l’architecture des ressources de stockage et de calcul. Les technologies de stockage NVMe se démarquent par leur bande passante plus élevée, une faible latence et des densités de stockage plus élevées.
Dans une architecture de calcul traditionnelle (voir figure 1), les données sont envoyées entre les plans de calcul et de stockage. Les ressources de calcul sont utilisées pour déplacer les données et traiter les données, effectuer la compression et la décompression, ainsi qu’une myriade d’autres tâches liées au système. Selon cette approche traditionnelle, les ressources de calcul disponibles doivent donc supporter une charge importante.
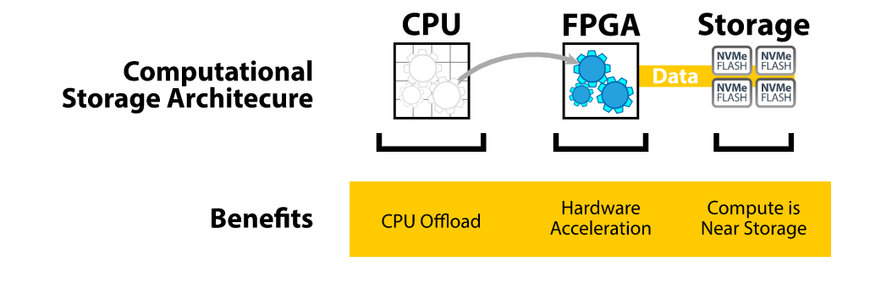
Figure 2 – Approche suivant l’architecture du computational storage. (Source : BittWare)
La mise en œuvre de l’architecture propre au computational storage constitue une approche plus efficace sur le plan des calculs (voir figure 2). Cette méthode affecte les tâches de calcul à un accélérateur matériel, lequel repose généralement sur un circuit logique programmable (FPGA). L’accélérateur matériel est connecté au stockage flash NVMe qui se trouve au même endroit. Le fait que les données soient stockées à proximité de là où les calculs sont effectués permet de réduire les opérations de transfert de données et par conséquent la charge de travail du processeur. Le FPGA faisant alors office de « processeur de stockage à capacité de calcul » (CSP, voir figure 3), il permet de libérer le processeur de n’importe quelle tâche gourmande en calcul (compression, chiffrement, inférence de réseau neuronal, etc.).
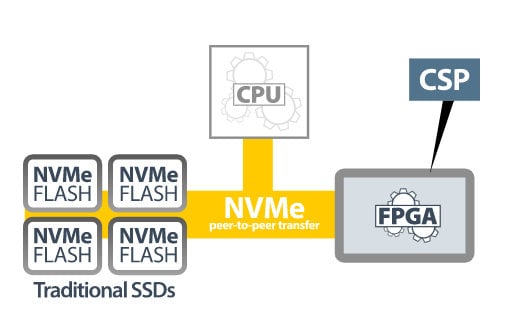
Figure 3 – Un processeur pour computational storage (CSP). (Source : BittWare)
L’IA-220-U2 de BittWare, un CSP à base de FPGA
Un exemple typique de CSP est l’IA-220-U2 de BittWare (lien Mouser ?). Il embarque un FPGA Intel Agilex avec 1,4 million d’éléments logiques, 16 Go de mémoire DDR4 et quatre interfaces PCIe de 4e génération. La SDRAM DDR4 affiche un taux de transfert maximal de 2.400 MT/s. Comme son nom l’indique, l’IA-220-U2 adopte le format U.2 conforme à la norme SFF-8639 pour disques de 2,5 pouces. Avec son dissipateur thermique refroidi par convection, ce CSP a été conçu pour s’intégrer dans des baies de stockage U.2 NVMe (voir figure 4).

Figure 4 – L’IA220-U2 de BittWare est conçu pour s’intégrer dans une baie de stockage U.2 standard. (Source : BittWare)
Ce CSP proposé par BittWare peut être remplacé à chaud (hot-swapping) et consomme aux alentours de 20 watts grâce à une alimentation U.2 hôte. Son déploiement en infrastructure d’entreprise et en centre de données est assuré par un contrôleur SMBus intégré compatible NVMe-MI, une fonction de contrôle flash SMBus FPGA et un accès SMBus aux capteurs de surveillance de tension et de température intégrés.
La figure 5 montre un schéma fonctionnel du BittWare IA-220-U2 illustrant toutes les fonctionnalités principales.
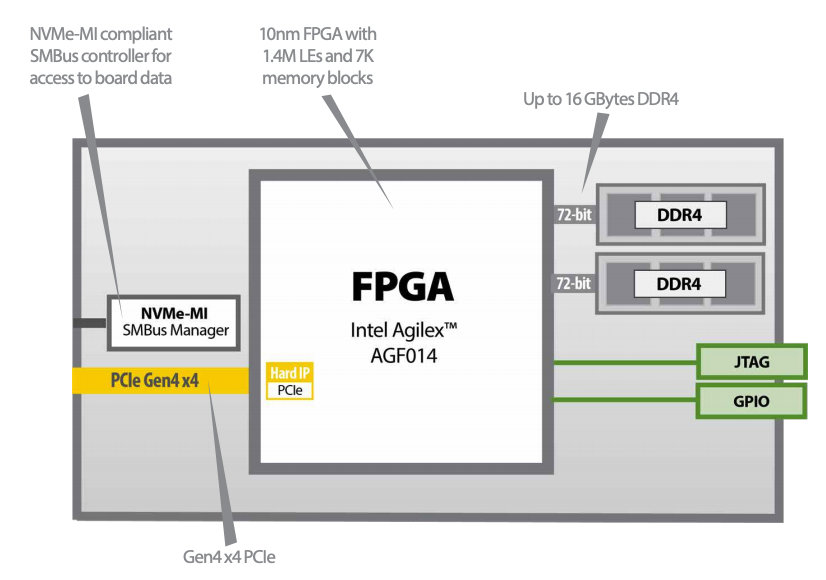
Figure 5 – Schéma fonctionnel du BittWare IA-220-U2. (Source : BittWare)
L’IA-220-U2 est conçu pour un large éventail d’applications et de tâches d’accélération impliquant de gros volumes de données, comme l’inférence d’algorithmes, la compression, le chiffrement et le hachage, la recherche d’images et le tri de bases de données ou encore la déduplication.
Implémentation d’un CSP avec l'IA-220-U2 de BittWare
Les clients ont la possibilité de programmer à leur guise l’IA -220-U2 de BittWare de façon à l’adapter au mieux aux besoins d’applications spécifiques, mais il peut aussi être déployé comme une solution préconfigurée grâce à l’IP NoLoad d’Eideticom.
BittWare fournit un SDK comprenant des pilotes PCIe, des utilitaires de surveillance de la carte et des bibliothèques de carte pour faciliter le développement personnalisé. Le logiciel Quartus Prime Pro d’Intel et des chaînes d’outils de synthèse et de flux de conception de haut niveau sont également fournis pour le développement d’applications FPGA.
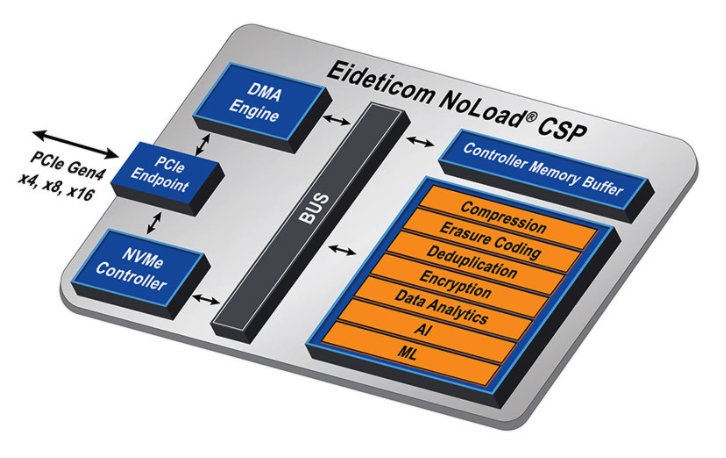
Figure 6 – Les fonctionnalités matérielles de l’IP NoLoad d’Eideticom (Source : BittWare)
L’IP NoLoad d’Eideticom comprend une pile logicielle intégrée plug-and-play complète basée sur le module BittWare U.2 en mode solution préconfigurée et embarque un ensemble de services de computational storage (CSS) avec accélération matérielle (voir figure 6, surlignage orange).
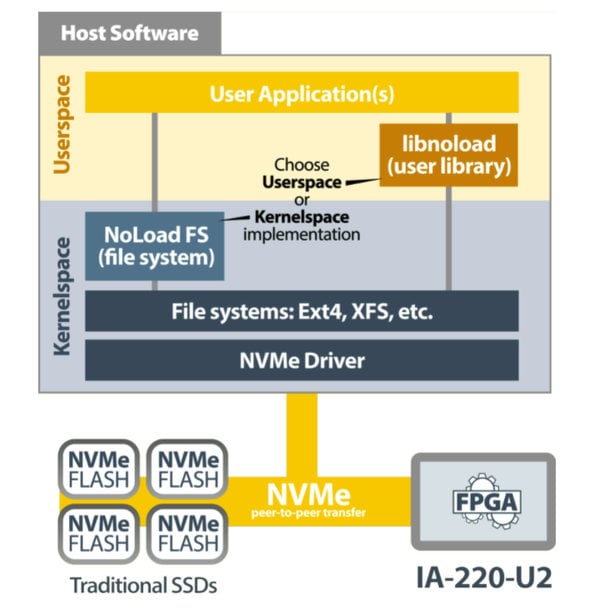
Figure 7 – Pile logicielle de l’IP NoLoad d’Eideticom. (Source : BittWare)
Les composants logiciels de l’IP NoLoad (voir figure 7) incluent un système de fichiers empilé dans l’espace du noyau et un pilote NVMe s’appuyant sur les CSS NoLoad et l’espace utilisateur orienté application Libnoload.
Le processeur NoLoad d’Eideticom constitue donc une solution souple capable de décharger le processeur en vue d’améliorer la qualité de service d’un facteur de 40 avec des attributs de faible puissance et pour un coût de possession global réduit.
Augmentez votre débit de données en déchargeant les tâches gourmandes en calcul
La mise en œuvre d’une architecture computational storage grâce au protocole NVMe offre des avantages considérables en termes de performances et d’efficacité énergétique pour le traitement de gros volumes de données. Cette approche réduit la nécessité de déplacer les données du périphérique de stockage vers le processeur et inversement en déchargeant les tâches gourmandes en ressources de calcul vers un CSP basé FPGA. Les données sont dès lors conservées dans des baies de stockage flash NVMe NAND à proximité de l’endroit où elles sont traitées, ce qui présente l’avantage de réduire l’utilisation de la bande passante et le temps de latence tout en économisant de l’énergie.
www.mouser.com
